Run a Benchmark#
Benchmarking helps you measure and compare the performance of different configurations, like machine types or simulation settings. It’s an essential step to reduce costs and speed up your simulations without losing accuracy.
In this tutorial, we’ll show you how to use Inductiva’s API to run a benchmark. We’ll use the SPlisHSPlasH simulator as an example, so you can follow along and learn the process step by step.
The goal is to find the best machine that balances computation time and cost. After running the benchmarks, we’ll analyze and visualize the results to make an informed choice.
What You’ll Learn#
In this tutorial, you’ll learn how to:
Download and prepare the necessary input files for the simulation.
Set up the benchmark.
Refine the code to reduce code redundancy and save benchmark costs.
Export the benchmark results.
Visualize and analyze results.
Let’s dive in!
Step 1: Download the Files#
Before we start benchmarking, we need to download the necessary input files for the SPlisHSPlasH simulator. These files include the configuration and assets required to run the simulations.
The code snippet below downloads the required simulation files to your working directory:
import inductiva
inductiva.utils.download_from_url(
url="https://tutorials.inductiva.ai/_static/generating-synthetic-data/splishsplash-base-dir.zip",
unzip=True)
Now you’re set to proceed with setting up the benchmark!
Step 2: Configure and Run the Benchmark#
Now that we have the necessary input files, let’s set up and execute the benchmark. We need to configure the benchmarking parameters, specify the machine types, and run the benchmark multiple times to ensure reliable results.
Here’s a look at the process:
1- Identify the Benchmark
Use benchmarks.Benchmark() to assign a name to the benchmark (e.g., splishsplash-fluid-cube) This name helps you track the benchmark results.
2- Add Simulation Runs
Add individual runs using the .add_run() method.
For each run, specify:
Simulator: The
simulators.SplishSplash()simulator for fluid dynamics.Input Directory: Path to the input files (“splishsplash-base-dir”) downloaded in Step 1.
Configuration File: Use the
config.jsonfile to define simulation parameters.Machine Type: Specify the machine type and configuration (e.g.,
c2-standard-4,c3-standard-44) usingresources.MachineGroup.
3- Run the Benchmark
Use .run(num_repeats=2) to execute all added runs, repeating each one twice.
Repeating runs helps ensure consistent and reliable performance metrics.
The following code example demonstrates the setup for testing c2-standard and
c3-standard machines:
from inductiva import benchmarks, simulators, resources
benchmarks.Benchmark(name="splishsplash-fluid-cube") \
.add_run(simulator=simulators.SplishSplash(),
input_dir="splishsplash-base-dir",
sim_config_filename="config.json",
on=resources.MachineGroup("c2-standard-4")) \
.add_run(simulator=simulators.SplishSplash(),
input_dir="splishsplash-base-dir",
sim_config_filename="config.json",
on=resources.MachineGroup("c2-standard-8")) \
.add_run(simulator=simulators.SplishSplash(),
input_dir="splishsplash-base-dir",
sim_config_filename="config.json",
on=resources.MachineGroup("c2-standard-16")) \
.add_run(simulator=simulators.SplishSplash(),
input_dir="splishsplash-base-dir",
sim_config_filename="config.json",
on=resources.MachineGroup("c2-standard-30")) \
.add_run(simulator=simulators.SplishSplash(),
input_dir="splishsplash-base-dir",
sim_config_filename="config.json",
on=resources.MachineGroup("c2-standard-60")) \
.add_run(simulator=simulators.SplishSplash(),
input_dir="splishsplash-base-dir",
sim_config_filename="config.json",
on=resources.MachineGroup("c3-standard-4")) \
.add_run(simulator=simulators.SplishSplash(),
input_dir="splishsplash-base-dir",
sim_config_filename="config.json",
on=resources.MachineGroup("c3-standard-8")) \
.add_run(simulator=simulators.SplishSplash(),
input_dir="splishsplash-base-dir",
sim_config_filename="config.json",
on=resources.MachineGroup("c3-standard-22")) \
.add_run(simulator=simulators.SplishSplash(),
input_dir="splishsplash-base-dir",
sim_config_filename="config.json",
on=resources.MachineGroup("c3-standard-44")) \
.add_run(simulator=simulators.SplishSplash(),
input_dir="splishsplash-base-dir",
sim_config_filename="config.json",
on=resources.MachineGroup("c3-standard-88")) \
.add_run(simulator=simulators.SplishSplash(),
input_dir="splishsplash-base-dir",
sim_config_filename="config.json",
on=resources.MachineGroup("c3-standard-176")) \
.run(num_repeats=2)
Step 3: Refine the Code#
As we add more machine types to the benchmark, the code can become repetitive and overwhelming. We need to sort the data out to make it easier to read and to ensure the benchmark setup remains concise, clear, and adaptable.
Improve Data Readability#
1. Simplifying the Code with set_default#
To make it cleaner and easier to manage, we can use the set_default method to define shared parameters like the simulator, input directory, and configuration file in one place. This reduces duplication and improves readability.
Here’s the updated code:
from inductiva import benchmarks, simulators, resources
benchmarks.Benchmark(name="splishsplash-fluid-cube") \
.set_default(simulator=simulators.SplishSplash(),
input_dir="splishsplash-base-dir",
sim_config_filename="config.json") \
.add_run(on=resources.MachineGroup("c2-standard-4")) \
.add_run(on=resources.MachineGroup("c2-standard-8")) \
.add_run(on=resources.MachineGroup("c2-standard-16")) \
.add_run(on=resources.MachineGroup("c2-standard-30")) \
.add_run(on=resources.MachineGroup("c2-standard-60")) \
.add_run(on=resources.MachineGroup("c3-standard-4")) \
.add_run(on=resources.MachineGroup("c3-standard-8")) \
.add_run(on=resources.MachineGroup("c3-standard-22")) \
.add_run(on=resources.MachineGroup("c3-standard-44")) \
.add_run(on=resources.MachineGroup("c3-standard-88")) \
.add_run(on=resources.MachineGroup("c3-standard-176")) \
.run(num_repeats=2)
2. Using a for Loop for Machine Types#
To simplify even further, we can define a list of machine types and use a for loop to programmatically add runs. This not only reduces the number of lines but also makes it easier to scale if more machine types are added later.
Here’s the updated code with a loop:
from inductiva import benchmarks, simulators, resources
benchmark = benchmarks.Benchmark(name="splishsplash-fluid-cube") \
.set_default(simulator=simulators.SplishSplash(),
input_dir="splishsplash-base-dir",
sim_config_filename="config.json")
machine_types = ["c2-standard-4", "c2-standard-8", "c2-standard-16",
"c2-standard-30", "c2-standard-60", "c3-standard-4",
"c3-standard-8", "c3-standard-22", "c3-standard-44",
"c3-standard-88", "c3-standard-176"]
for machine_type in machine_types:
benchmark.add_run(on=resources.MachineGroup(machine_type))
benchmark.run(num_repeats=2)
Optimizing the Benchmark Program#
We can optimize how the benchmark program manages input files, machine resources, and execution parameters to reduce computation time and cost. This step ensures the program runs efficiently while avoiding unnecessary resource usage.
1. Reuse Input Files Across Runs
Uploading input files for every run can waste time and resources. Instead, we upload the files once to a GCP bucket and reuse them for all subsequent runs. We’ve already covered this feature in detail in a tutorial on How to Reuse Input Files Across Runs, so feel free to check it out for a detailed walkthrough.
Upload Files to a GCP Bucket
Use the inductiva.storage.upload function to upload the input files to a GCP bucket:
import inductiva
inductiva.storage.upload(local_path="splishsplash-base-dir",
remote_dir="splishsplash-input-dir")
This stores the input files in the splishsplash-input-dir bucket, making them
accessible to all runs.
Configure the Benchmark to Use Remote Files
Update the benchmark configuration to use the uploaded files by specifying the remote_assets parameter in set_default. Remove the input_dir parameter since the files are now accessed remotely:
# ...
benchmark = benchmarks.Benchmark(name="splishsplash-fluid-cube") \
.set_default(simulator=simulators.SplishSplash(),
sim_config_filename="config.json",
remote_assets=["splishsplash-input-dir"])
# ...
2. Parallelize Benchmark Execution
To speed up benchmark execution, run multiple repetitions in parallel by setting the num_machines parameter equal to the number of repetitions (num_repeats). Each machine in the group will handle one repetition:
# ...
num_repeats = 2
for machine_type in machine_types:
benchmark.add_run(on=resources.MachineGroup(machine_type=machine_type,
num_machines=num_repeats))
# ...
This ensures simulations are distributed across multiple machines, significantly reducing runtime.
3. Minimize Idle Time
Idle resources increase costs. To avoid this, set a maximum idle time for each machine to avoid wasting computational resources and, as a result, decrease the benchmark cost. Here’s how to configure it with max_idle_time:
# ...
max_idle_time = datetime.timedelta(seconds=30)
for machine_type in machine_types:
benchmark.add_run(on=resources.MachineGroup(machine_type=machine_type,
num_machines=num_repeats,
max_idle_time=max_idle_time))
# ...
Note: Reducing idle time too much may cause errors if the simulations cannot be submitted quickly enough. Adjust the value based on your setup.
Here is the final, optimized, and refactored version of the benchmark program:
import datetime
from inductiva import benchmarks, simulators, resources
benchmark = benchmarks.Benchmark(name="splishsplash-fluid-cube") \
.set_default(simulator=simulators.SplishSplash(),
sim_config_filename="config.json",
remote_assets=["splishsplash-input-dir"])
machine_types = ["c2-standard-4", "c2-standard-8", "c2-standard-16",
"c2-standard-30", "c2-standard-60", "c3-standard-4",
"c3-standard-8", "c3-standard-22", "c3-standard-44",
"c3-standard-88", "c3-standard-176"]
num_repeats = 2
max_idle_time = datetime.timedelta(seconds=30)
for machine_type in machine_types:
benchmark.add_run(on=resources.MachineGroup(machine_type=machine_type,
num_machines=num_repeats,
max_idle_time=max_idle_time))
benchmark.run(num_repeats=num_repeats)
Step 4: Export the Benchmark Data to a File#
Once the benchmark is complete, you’ll want to save the results for analysis. In this step, we’ll export the benchmark data to a CSV file. Additionally, we’ll ensure all benchmark-related tasks are finished and resources are properly terminated.
1- Exporting the Benchmark Data
The benchmark results can be exported to a file using the export method.
This allows you to filter the data and customize the output format.
For this example, we’ll:
Export the results of the benchmark named
splishsplash-fluid-cube.Save only successful tasks (
status="success").Include only attributes and metrics that vary between runs (
select="distinct").Save the results in a file named
benchmark.csv.
2- Completing the Benchmark Process
Before exporting the data, it’s important to ensure:
All benchmark-related tasks are completed using the
wait()method.All resources used during the benchmark are terminated to avoid unnecessary charges by calling
terminate().
Here’s the full code:
from inductiva import benchmarks
benchmarks.Benchmark(name="splishsplash-fluid-cube") \
.wait() \
.terminate() \
.export(fmt="csv",
status="success",
select="distinct",
filename="benchmark.csv")
Step 5: Visualize and Analyze the Benchmark Results#
After exporting the benchmark results, the next step is to analyze the data to determine the best machine configuration based on computation time and cost.
Visualizing the Results#
You can use a tool like CSVPlot to upload and visualize the exported CSV file. Follow these steps:
Open the CSVPlot website.
Upload the benchmark.csv file containing the results.
Generate a plot to compare computation time and cost for each machine type.
Key Insights from the Plot#
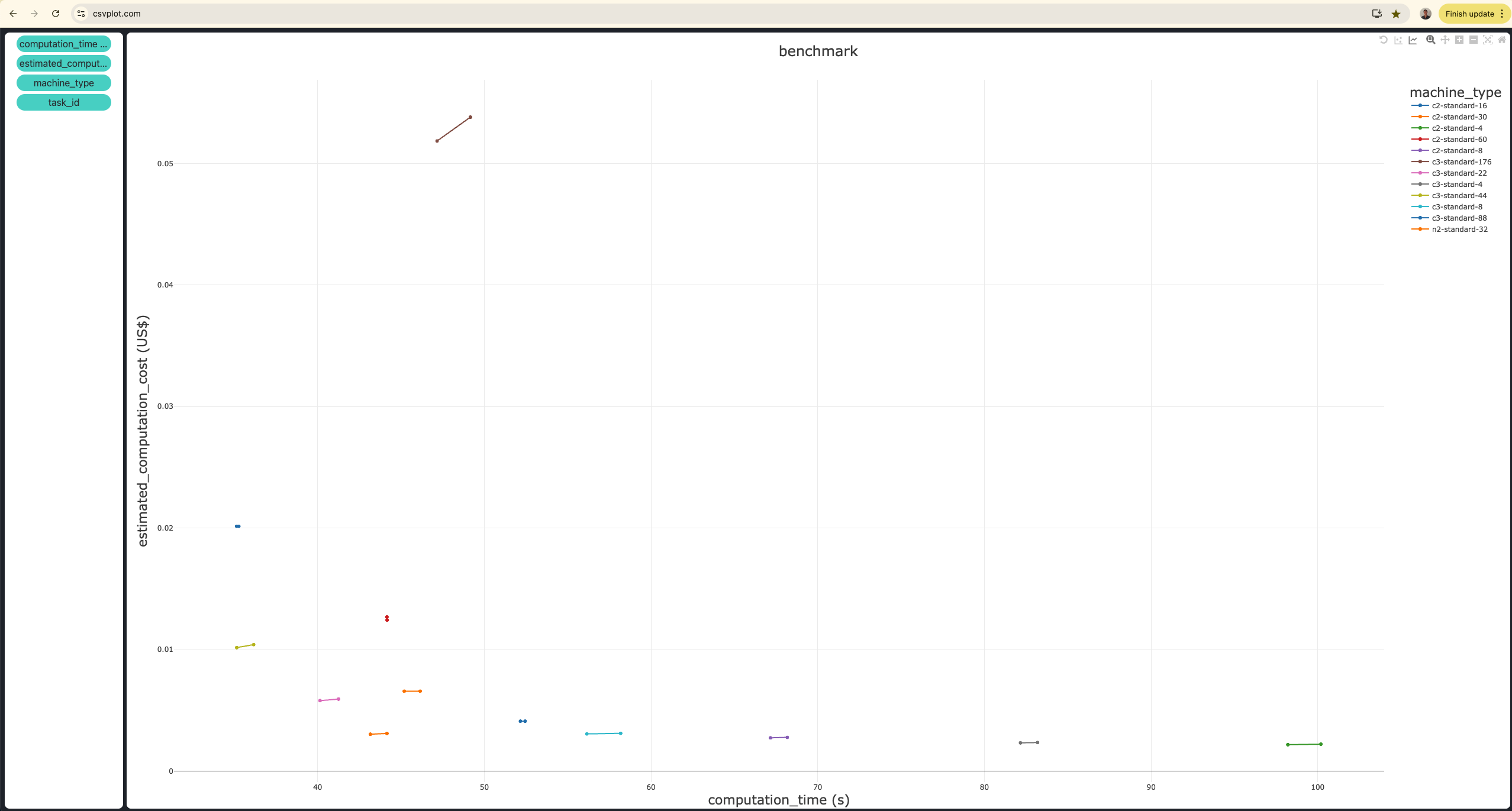
The
c3-standard-44machine is the best in terms of both computation time and cost.It takes approximately 35 seconds and costs $0.01.
The
c3-standard-88machine takes the same amount of time but costs twice as much.
Bonus: Adding a New Machine for Comparison#
You may decide to test additional machines after completing the initial benchmark. For instance, let’s add the n2-standard-32 machine to the existing benchmark and execute only this run.
Steps to Add a New Machine
Recreate the benchmark using the same name (
splishsplash-fluid-cube).Add a new run for the
n2-standard-32machine type.Set
num_repeats=2to execute the run twice.
Here’s the code:
import datetime
from inductiva import benchmarks, simulators, resources
num_repeats = 2
max_idle_time = datetime.timedelta(seconds=30)
benchmark = benchmarks.Benchmark(name="splishsplash-fluid-cube") \
.add_run(simulator=simulators.SplishSplash(),
sim_config_filename="config.json",
remote_assets=["splishsplash-input-dir"],
on=resources.MachineGroup(machine_type="n2-standard-32",
num_machines=num_repeats,
max_idle_time=max_idle_time)) \
.run(num_repeats=num_repeats)
With this step, your benchmark analysis is complete, and you now have the tools to continuously refine and expand your benchmarking experiments.