Benchmarking Computational Resources#
In the previous step of this tutorial, we used Inductiva’s templating mechanism to transform the configuration files for our base case simulation into a generalized file, allowing programmatic changes to key parameters. These parameters included dimensions, initial position and velocity of the fluid block, as well as the density and viscosity of the fluid itself, essential elements that define the core physical properties of the simulation.
Additionally, we generalized certain hyperparameters that influence the simulation’s fidelity and performance. For example, we adjusted the period of time and the particle radius to control both the computational effort and the execution time of the simulation.
The first hyperparameter, the period of time, determines how long we want the simulation to run. For example, do we want 5 seconds or 10 seconds of fluid splashing? Naturally, the longer the period of time, the more computational time it will require, with this relationship expected to be linear.
The second hyperparameter is the particle radius. While this parameter is not directly related to the physical properties of the fluid being simulated, it significantly affects the numerical stability and resolution of the underlying SPH algorithm, and plays a crucial role in the physical fidelity of the simulation results. As the particle radius decreases, more particles are needed to represent the fluid, making the simulation more computationally expensive. Unlike the period of time, this relationship is not linear; the number of particles required to represent the same fluid’s volume increases in O(n³) as the particle radius decreases.
When running simulations, balancing speed and cost is critical to achieving
efficient workflows. In this step, we focus on benchmarking various computational
resources to identify the best machine type for our simulations. To ensure consistency, we fixed the parameters related to
the period of time and particle radius (i.e., "stopAt": 4, "timeStepSize": 0.01, and
"particleRadius": 0.01, as described here). These settings allowed us to evaluate performance across different machine types under the
same conditions.
Why Benchmark?#
Inductiva’s computations currently run on Google Cloud VMs (Virtual Machines),
which offer a wide variety of options at different price points. Google Cloud
provides VMs from multiple machine families—such as c2, c2d, and c3—each
designed for specific performance needs.
These VM families differ in their underlying physical hardware:
CPUs: Different processor generations and architectures
RAM: Memory capacity and bandwidth.
Performance: Hardware optimizations that affect speed, parallelization, and latency.
Some simulation software is optimized to take advantage of specific hardware configurations, meaning their performance can vary significantly across different VM families. Surprisingly, in some cases, simulations may perform better on less expensive VMs compared to pricier alternatives. As we’ll demonstrate later in this benchmark, choosing the right machine type isn’t always about cost, it’s about finding the best match for your software’s needs.
VMs also allow you to configure the number of virtual CPUs (vCPUs), ranging
from as few as 4 to several dozen, or even hundreds, on machine families
like c2d and c3d. While increasing the number of vCPUs generally speeds
up simulations, scaling is rarely linear.
There’s often a “sweet spot” where performance gains flatten out as parallelization efficiency decreases. Beyond this point, using more vCPUs may result in diminishing returns, where costs rise faster than the benefits of additional speed. We’ll explore this tradeoff in detail in the benchmark results later.
Defining the Benchmark Parameters#
To benchmark the performance and cost-efficiency of different machine types, we need to evaluate computation times and scalability without unnecessary overhead.
Let’s see how to benchmark the water fluid simulation on multiple cloud machines using the Inductiva API!
First, we need to download the necessary input files. This step is needed because the benchmark requires specific data to
simulate the WaterCube environment. The code snippet uses the download_from_url method to download and unzip the
required files directly into your local directory. You can skip this step if you already have the input files in your local
directory.
import inductiva
inductiva.utils.files.download_from_url(
url="https://tutorials.inductiva.ai/_static/generating-synthetic-data/"
"splishsplash-base-dir.zip",
unzip=True)
Once the input files are downloaded, it’s a good idea to upload them to a remote storage location. This step prevents you from having to re-upload the input files every time you execute a run during the benchmark, which can save time (e.g., reduces setup time) when you’re executing multiple runs (i.e., simulations). In other words, uploading the files ensures that they can be accessed across different benchmark runs and it also helps manage resources more efficiently.
import inductiva
inductiva.storage.upload(local_path="splishsplash-base-dir",
remote_dir="splishsplash-input-dir")
Now comes the core of the benchmarking process: configuring the benchmark with the desired settings and running it across
multiple machine types. In this step, you will define the benchmark parameters, such as the simulator used, the simulation
configuration file, and the remote assets (i.e., the input files you just uploaded). The benchmark is configured to run
across a range of machine families, from the less powerful c2-standard machine types to the more powerful c3-standard
machine types, each with varying numbers of vCPUs. Each run is repeated twice to ensure reliable and consistent results.
import datetime
from inductiva import benchmarks, simulators, resources
benchmark = benchmarks.Benchmark(name="Benchmark-SPlisHSPlasH-WaterCube") \
.set_default(simulator=simulators.SplishSplash(),
sim_config_filename="config.json",
remote_assets=["splishsplash-input-dir"])
machine_types = [
"c2-standard-4", "c2-standard-8", "c2-standard-16", "c2-standard-30",
"c2-standard-60", "c3-standard-4", "c3-standard-8", "c3-standard-22",
"c3-standard-44", "c3-standard-88", "c3-standard-176",
]
num_repeats = 2
max_idle_time = datetime.timedelta(seconds=30)
for machine_type in machine_types:
benchmark.add_run(on=resources.MachineGroup(machine_type=machine_type,
num_machines=num_repeats,
max_idle_time=max_idle_time))
benchmark.run(num_repeats=num_repeats)
An important point to note is that the SPlisHSPlasH simulator automatically handles parallelization, taking full advantage of the increased number of vCPUs on a machine without requiring additional configuration. This is not true for all simulators, such as Reef3D, which requires updating certain parameters in the configuration files.
Exporting and Visualizing Results#
Once the benchmarking runs are complete, it’s time to analyze the data and extract insights. To make this process straightforward, we stored the benchmark results in a structured format (CSV), which makes it easy to share, analyze, and visualize the findings.
from inductiva import benchmarks
benchmarks.Benchmark(name="Benchmark-SPlisHSPlasH-WaterCube") \
.wait() \
.terminate() \
.export(fmt="csv")
Finally, the benchmark results are ready to be analyzed and visualized. In this step, we turn the raw CSV data into a more readable format, either as a table or a plot, to better understand the performance metrics.
The first way to visualize the data is by converting the CSV into a Markdown table. This provides a clean, readable summary of the results, helping you compare different machine types side-by-side. You can use this online tool to convert the CSV file into a Markdown table format.
| machine_type | estimated_computation_cost (US$) | computation_time (s) | task_id |
|-----------------|----------------------------------|----------------------|---------------------------|
| c3-standard-176 | 0.053812210494 | 49.174 | 0bgkh9xx16eui51ijxtb6ux86 |
| c3-standard-176 | 0.054790614321 | 49.181 | n61gv7tfkci6e80jjiqvodsdv |
| c2-standard-60 | 0.013439589506 | 44.144 | 0h701znoed7tfiv2wh0v6ydw6 |
| c2-standard-60 | 0.012932435185 | 45.159 | n5upfe2n35wtk1qe48pzjh7ez |
| c3-standard-88 | 0.020144276914 | 35.139 | 469k83ppb37zi8xjadqejz2cg |
| c3-standard-88 | 0.020635600741 | 36.233 | mconyhtckc0rs6cc3jjnkoyh0 |
| c3-standard-22 | 0.006552719013 | 40.148 | ed08ydiknndtdkv7s3nh4sp4t |
| c3-standard-22 | 0.005922649877 | 40.248 | 0422m5s30n0uxmiyy00bg3uo1 |
| c3-standard-8 | 0.003105524938 | 58.183 | qu0kf1cqpwc85yye8su34ond2 |
| c3-standard-8 | 0.003154048766 | 58.175 | cea52xxuj1tvxhwu1ruw7c0nv |
| c3-standard-4 | 0.002348160618 | 83.18 | r47bemyjyjzy4x0fhxeqm33bj |
| c3-standard-4 | 0.002374544445 | 84.182 | 91aoeet96m3di0wa429u1k4s3 |
| c3-standard-44 | 0.011645839877 | 36.152 | t8ajechar6rhstg1j71wpa0j9 |
| c3-standard-44 | 0.010654704568 | 36.155 | irxjh6wxcus044e15uhhy1ww7 |
| c2-standard-8 | 0.002924085185 | 71.496 | 8kb27eno9qajnpyx5pnubqzat |
| c2-standard-4 | 0.002211801235 | 100.209 | ts13hykwxhgoamgczndsiyy96 |
| c2-standard-30 | 0.006574435185 | 45.174 | 2sceirkj0dm1ye2v923ri5ziq |
| c2-standard-8 | 0.002961573457 | 73.101 | 89aomezvc6mznu2q89u84vjan |
| c2-standard-30 | 0.006574435185 | 45.172 | 4xau4bu9ikogmycqtwmv2ybdo |
| c2-standard-4 | 0.002211801235 | 99.237 | 6a12iau416t567v15swn7ir78 |
| c2-standard-16 | 0.004102497531 | 52.169 | tv7cy85r83u0sofgir5m8t8i3 |
| c2-standard-16 | 0.004314695679 | 55.172 | c6f0bbbcdpcb88eorsyvwvms2 |
The Results Are In: Our Simulation’s “Sweet Spot” for Speed and Cost#
Finally, our results are in! We used CSV plot, an online tool, to plot the benchmark results on a graph and have a better visual of the data.
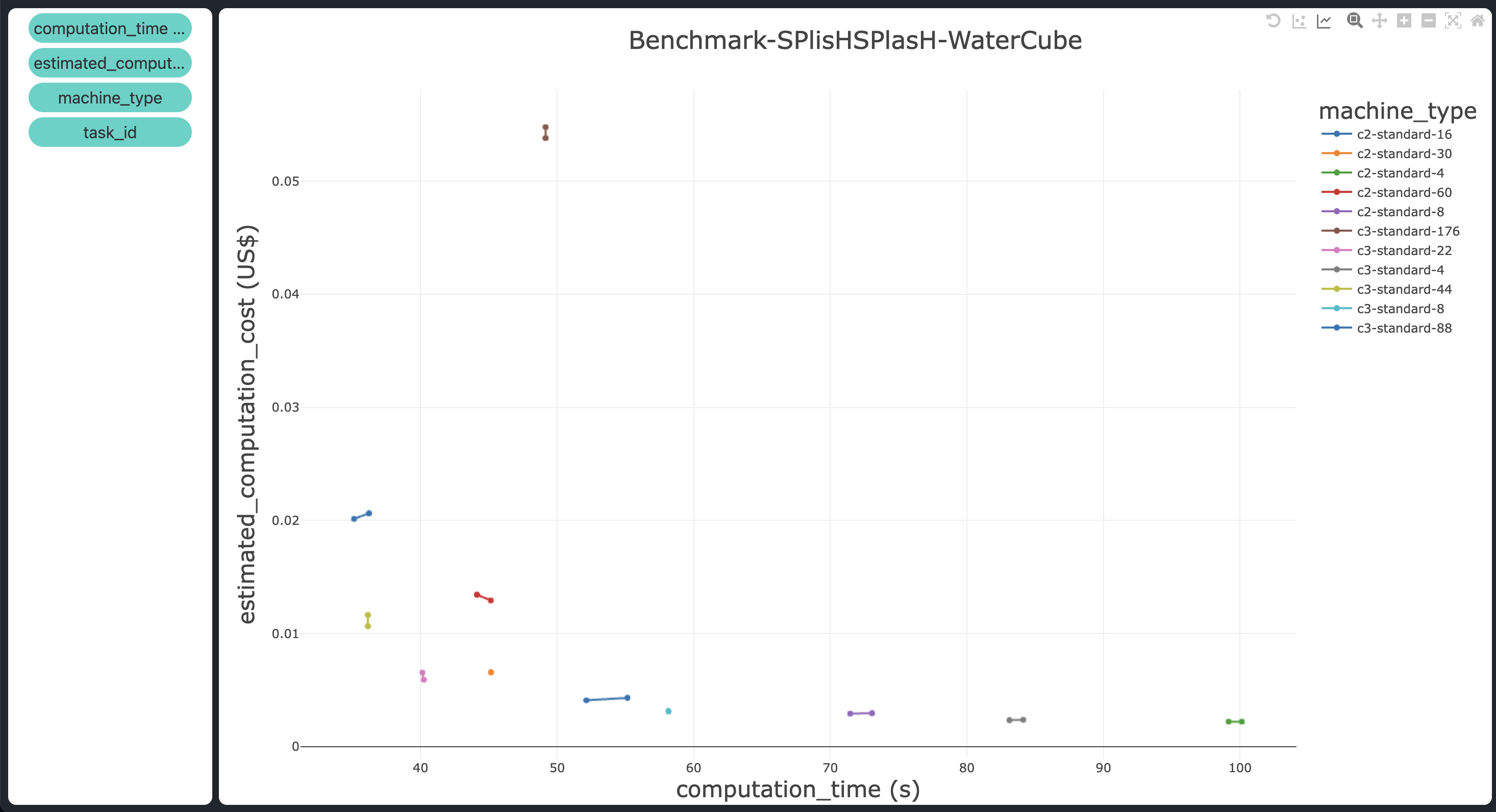
When observing the graph, we easily identified which machine types provide the best balance between computation time and cost for our simulation.
Here are the key takeaways:
The best machine types in terms of computation cost and computation time are
c3-standard-44andc3-standard-22, with the latter being slightly slower but more cost-effective – positioned in the leftmost bottom corner of the plot. They take 35 and 40 seconds, respectively, and cost $0.01 and $0.005 each.The speedup in terms of execution time levels off at 44 vCPUs. The
c3-standard-88takes the same computation time as thec3-standard-44(around 36 seconds) but costs twice as much to execute the simulation ($0.02 compared to $0.01, respectively). An even clearer indication of this plateau in speedup is that the most powerful machine, thec3-standard-176, is actually slower than an older-generation machine with far fewer vCPUs, thec2-standard-30(around 49 seconds vs. 45 seconds, respectively). Moreover, it costs 10 times more ($0.06 vs. $0.006). This significant cost disparity highlights the critical role of benchmarking: choosing the right machine can save you 10x or more in costs for the same simulation execution, without compromising computation time.The computation time starts to increase more rapidly when the number of vCPUs is reduced below 16 (from 50 seconds to 100 seconds), while the cost remains relatively constant at around $0.002.